


All about ML Monitoring in Finance

Today’s newsletter is all about Finance and ML. We've been working with data science teams in the financial sector for a long time. They are probably the industry that has adopted ML Monitoring into their workflows faster, likely because their ML models are critical to day-to-day operations.
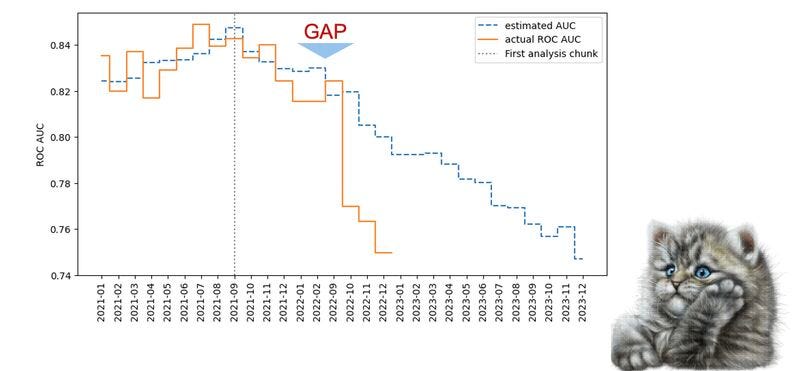
That said, the industry generally is still falling short at capturing the real model issues. This is especially true in organizations that follow what we call the “Tradition ML Monitoring” framework, which is when systems only track basic drift detection metrics, and model performance can only be calculated when ground truth is available.

So, if the traditional way is not the way to go, what is it?
Last week, Anton Bagin, Senior Data Scientist at Bereke Bank, and Wojtek Kuberski, NannyML CTO, hosted an awesome webinar about “Alternative Model Monitoring in Banking.”
Anton presented a Case Study on Improving Loan Default Predictions. The entire talk is incredible. They explain how you can benefit by:
Using confidence-based performance estimation methods to estimate any performance metric before ground truth is available.
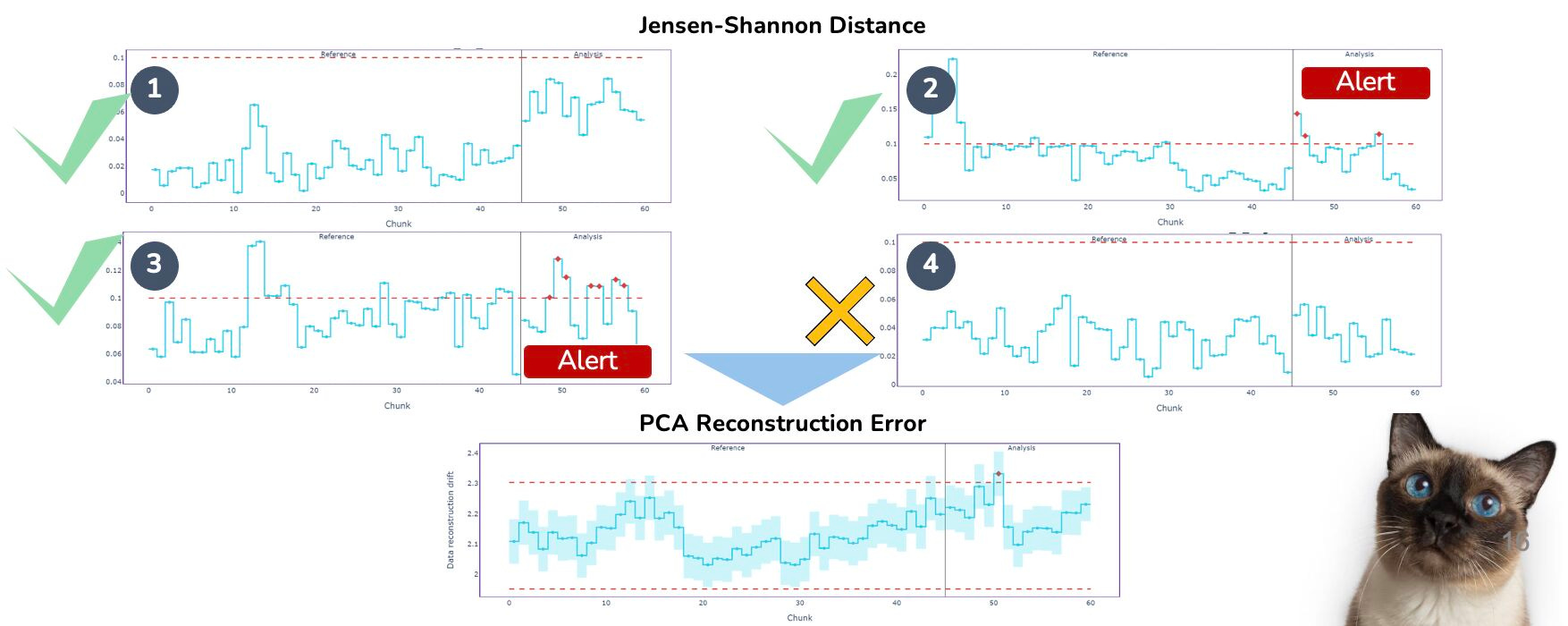
Not relying on data drift as your primary monitoring layer; instead, use it to explain performance issues.
Recording of the talk:
Summary from the webinar
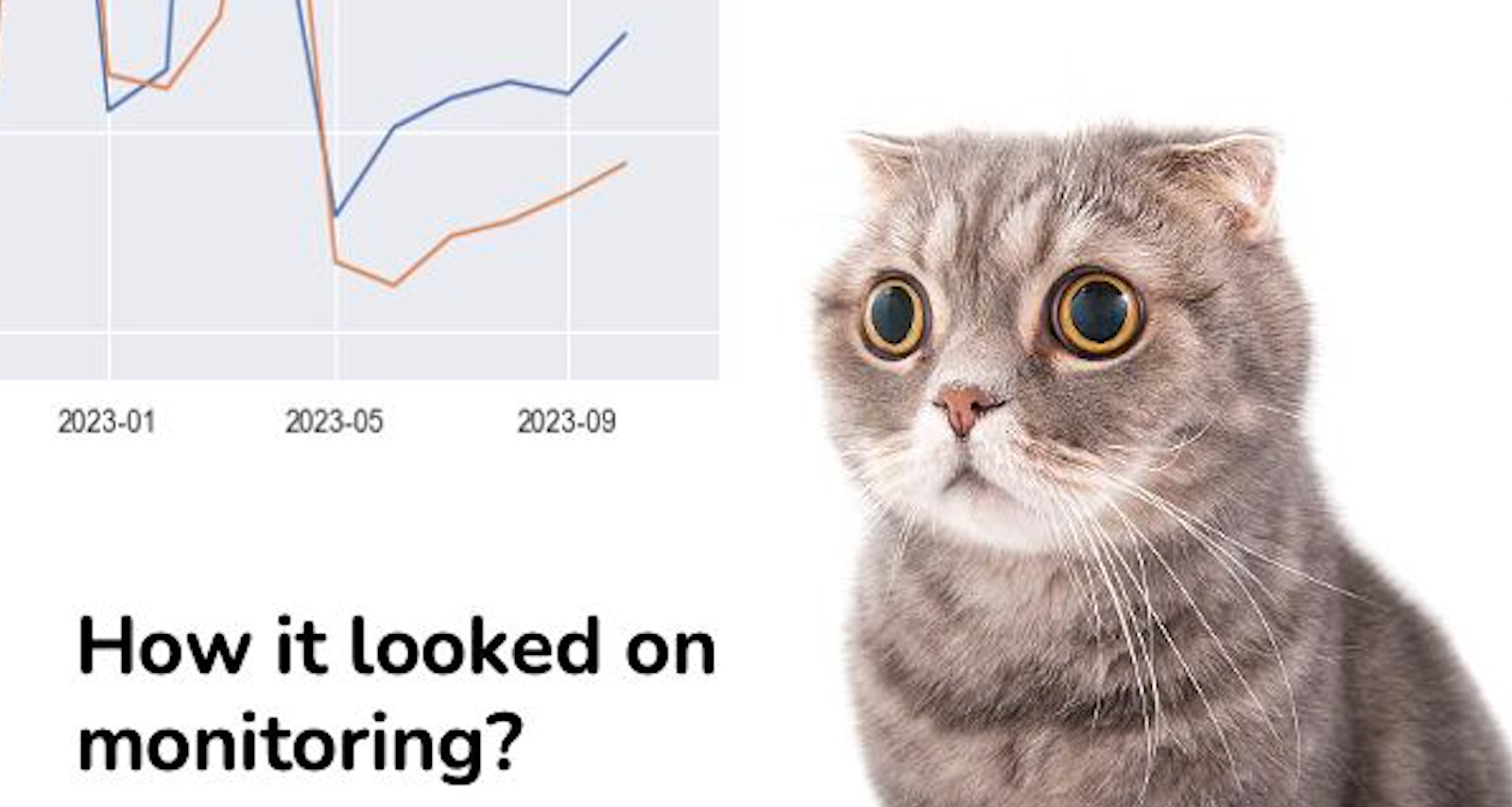
In case you are in a rush and don’t have time to check the recording, you can check Anton’s summary, where he explains some of the concepts covered in the webinar. (You will find his posts purrfect 🤭).

NannyML + Finance
With Anton’s and Wojtek’s talk, we officially kick off NannyML’s first vertical solution in Finance. We are working with data science teams in the financial sector to learn more about their needs and how we can build solutions tailored to their use cases.
🔗 Check out our resources to learn more about NannyML + Finance.

Shoutout to the community 💜
First, a huge thank you to Anton for hosting a fantastic webinar—and for all the cats!
Abhishek Pawar, thanks for the kind words about our content!

Random Reddit user, the timing of you comment, was perfect 🫶

Carl McBride Ellis, thanks for your support with The Little Book of ML Metrics.



Some Exciting News 👀
Wojtek and I are writing a book on ML Metrics.
Metrics are arguably the most important part of data science work, yet they are rarely taught in courses or university degrees. Even senior data scientists often have only a basic understanding of metrics—literally, almost nobody knows what happens to MAPE if we scale the targets to a standard normal distribution.

P.S.: we’re also including business specific metrics for various industries (including finance). According to many data scientists in finance, sharp ratio is an important one.
I’m hooked. Tell me more…
The idea of the book is to be this little handbook that lives on top of every data scientist's desk for quick reference of the most known metric, ahem, accuracy, to the most obscure thing (looking at you, P4-metric)
➡️ Pre-order your copy here: https://www.nannyml.com/metrics or DM Santiago if you want to help review/contribute to any specific section.
Excited about NannyML’s monitoring capabilities + Finance?
Check out what we have to offer at https://www.nannyml.com/solutions/finance and book a call to learn more!